Upload your own documents for LLM to analyze using RAG
What is RAG, Retrieval-Augmented Generation?
All LLMs have a cut-off date for its latest information. For e.g., OpenAI GPT4o has info up to Nov 2023 (i think).
How do i give the LLM latest information?
Also, what if I want LLMs to analyze my personal documents?
In ChatGPT, you can actually attach your documents and get ChatGPT to analyze your files. RAG is like that.
Except what is happening in ChatGP is NOT rag: ChatGPT actually copies and append your entire documents into your prompt. This takes up a lot of tokens sent to the LLM.
In RAG, the documents are not send to the LLMs. This reduces costs for you.
I got ChatGPT to help me explain rag
“RAG” stands for Retrieval-Augmented Generation. It might sound a bit technical, but here’s a beginner-friendly explanation:
Imagine a Super Smart Research Assistant
Two Parts of the System:
Retrieval: Think of this like a super-fast librarian. When you ask a question, this part quickly searches through a huge library of documents (or a database) to find the most relevant pieces of information.
Generation: Once the librarian gathers the important bits, this part acts like a brilliant writer who uses that information to craft a clear and informative answer. How It Works Together:
Step 1: You Ask a Question: For example, “What are the benefits of renewable energy?”
Step 2: Retrieval Phase: The system searches its database or collection of documents to find text snippets, articles, or data that are relevant to renewable energy.
Step 3: Generation Phase: With the relevant information in hand, the system then uses a language model (like the one behind ChatGPT) to generate a coherent answer that combines what it knows with the newly retrieved information.
Why Use RAG?
Up-to-date Answers: Traditional language models are trained on data up to a certain point in time. With RAG, even if the model’s training data is old, it can pull in recent or specialized information from the retrieval part.
Better Accuracy: By basing answers on real documents, the system can reduce the chance of “hallucinating” (making up information) and provide more accurate, verifiable responses.
Efficiency: Instead of trying to memorize everything, the model leverages external information, which makes it more flexible and knowledgeable.
In Summary:
Retrieval: Finds relevant information from a large collection.
Generation: Uses that information to produce a coherent, accurate answer.
Together: They make a system that can provide informed and current answers, even on topics that the model might not have been originally trained on.
But… in Open WebUI, I can also just attach a file to the Chat.
Yes you can do that too! What we are doing below is to set up a more permanent type of knowledge that you can use in any future chats.
But also note: this upload is still a rag. It is NOT like what you do in ChatGPT official app.
Step 1: Log In to OpenWeb UI through Docker
Remember to open up Ollama as well!
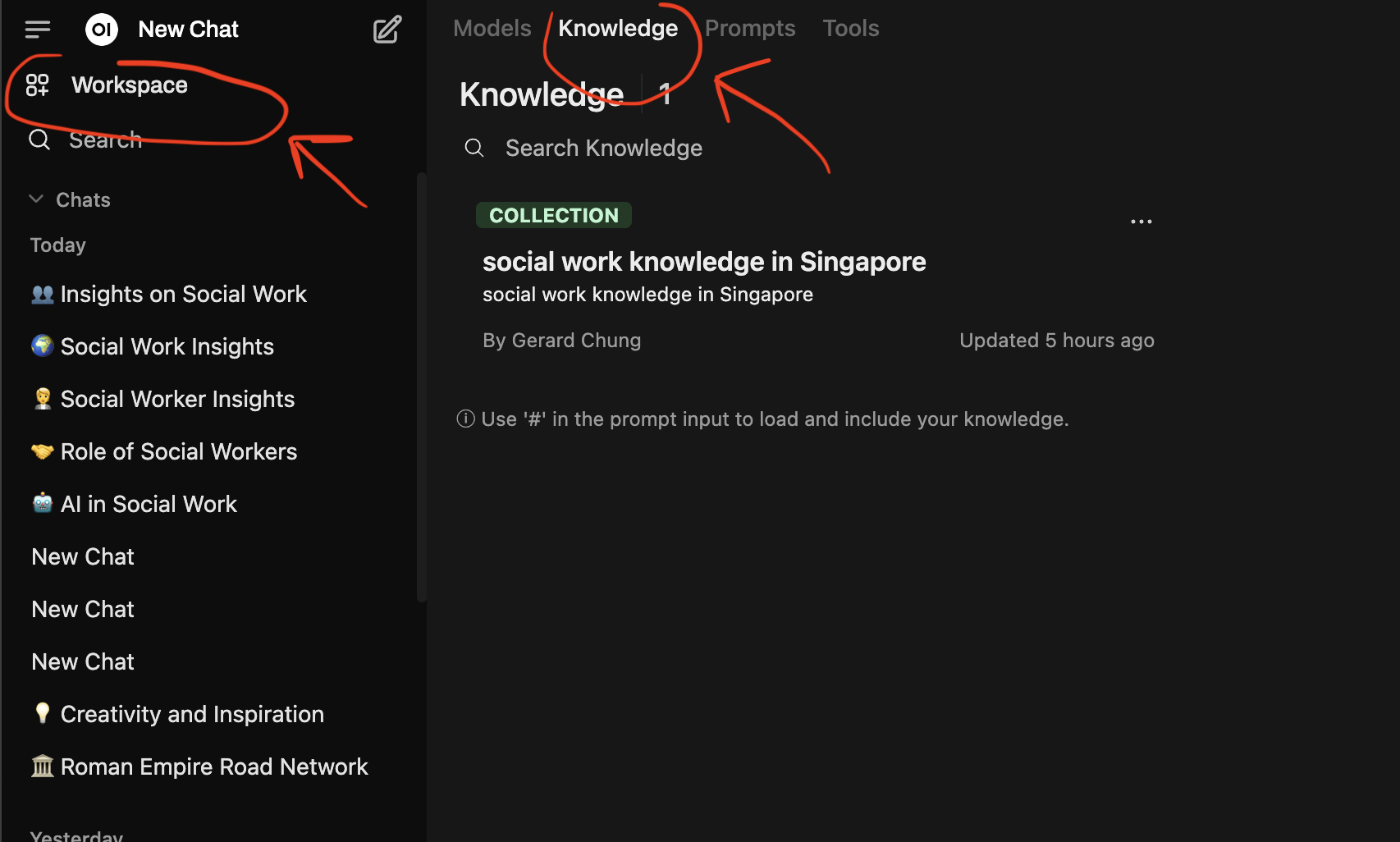
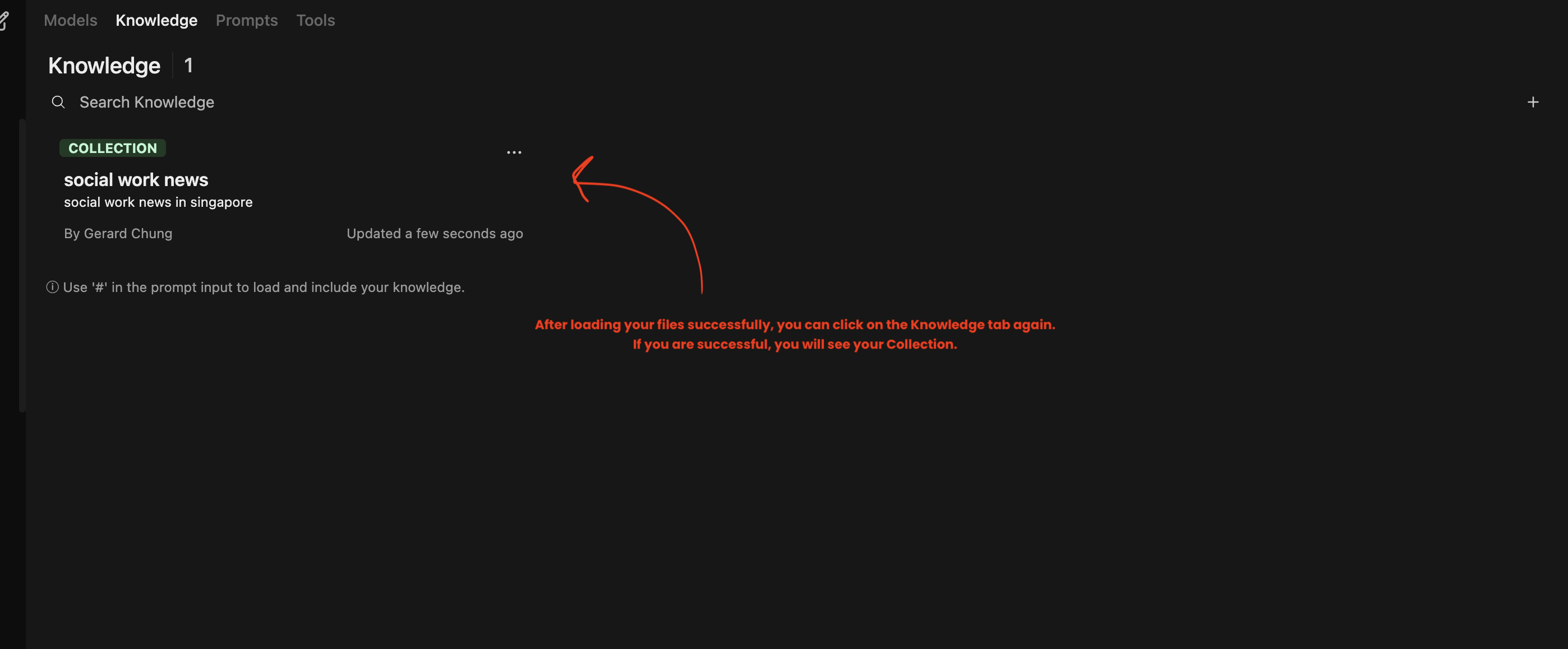
Step 2: Click on “Workspace” -> “Knowledge”
You will be able to upload your documents here and save them as collections. If you have previously uploaded, you will see it here. For instance in my set-up, I have created a collection called “social work knowledge in Singapore” and uploaded docs into the collection.
Let’s do this now for you. Click on the “+” on the right to add in your files.
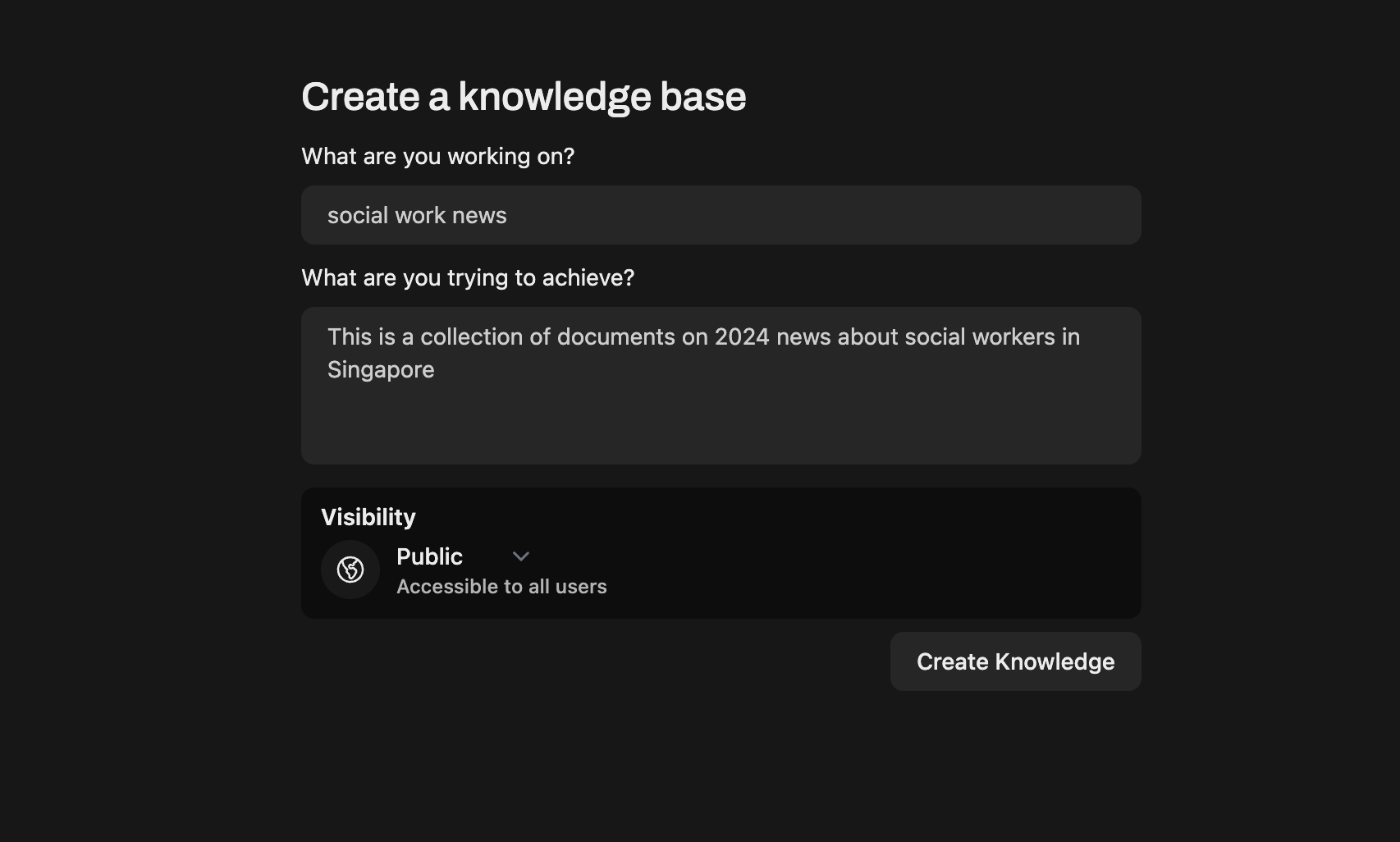
Step 3: Click “+” and give a name and a description to your collection.
I would say to give name that is short and information, i.e. it will help you to know what is the collection about.
This is because later on, you can actually call on the knowledge by “hash-tagging” the knowledge when using the LLM!
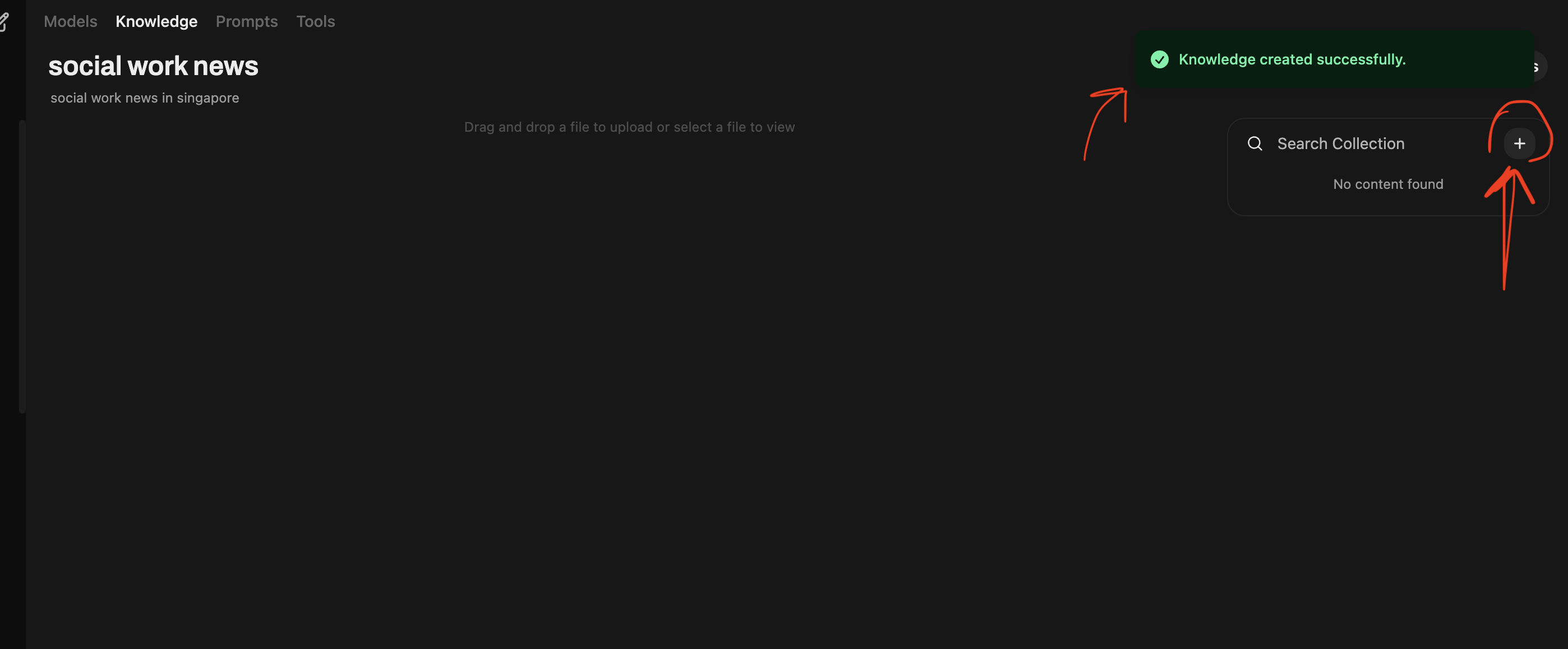
Step 4: Upload your documents
The documents uploaded will only be stored on your computer. They do not get sent somewhere else. You can always come back to delete or add files!
You can use your own documents or if you want to follow this example, use my folder of 12 news articles about Social Worker in Singapore. Download here
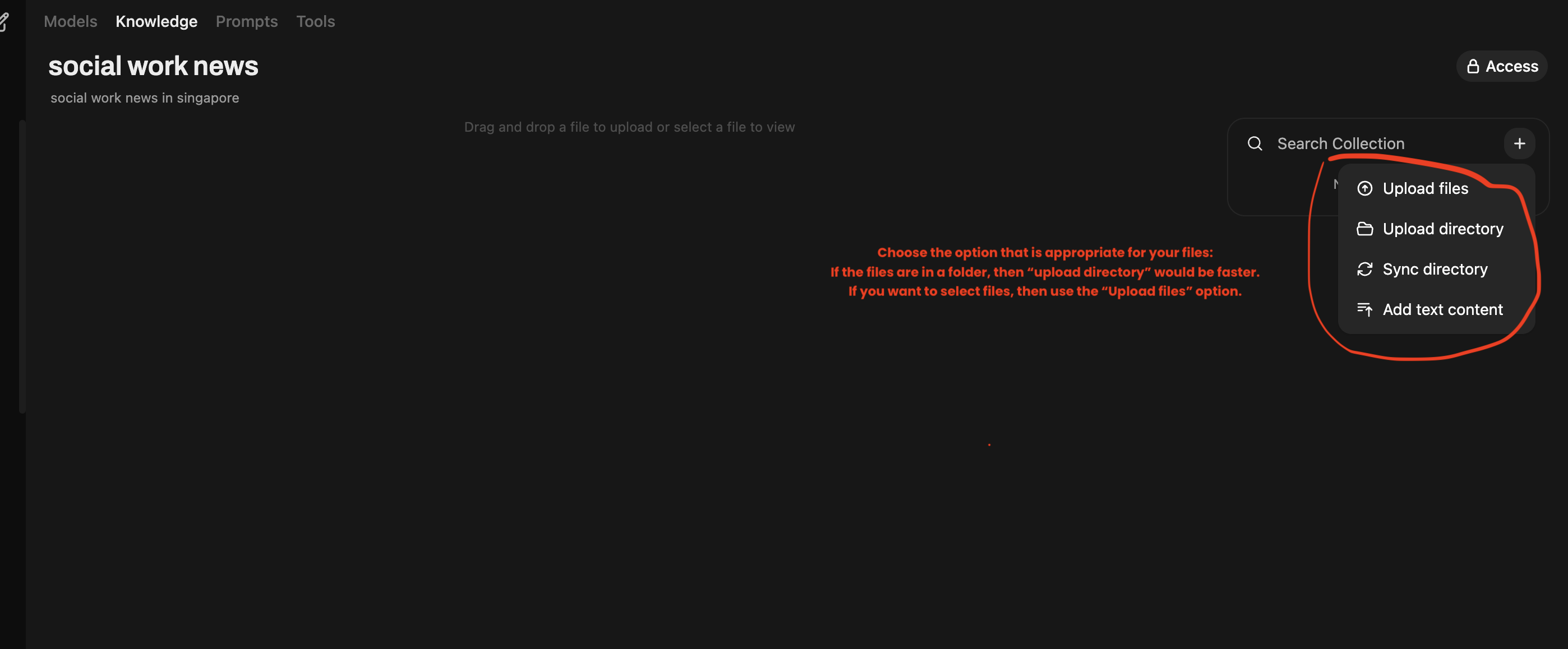

That is it. Your files have been uploaded.
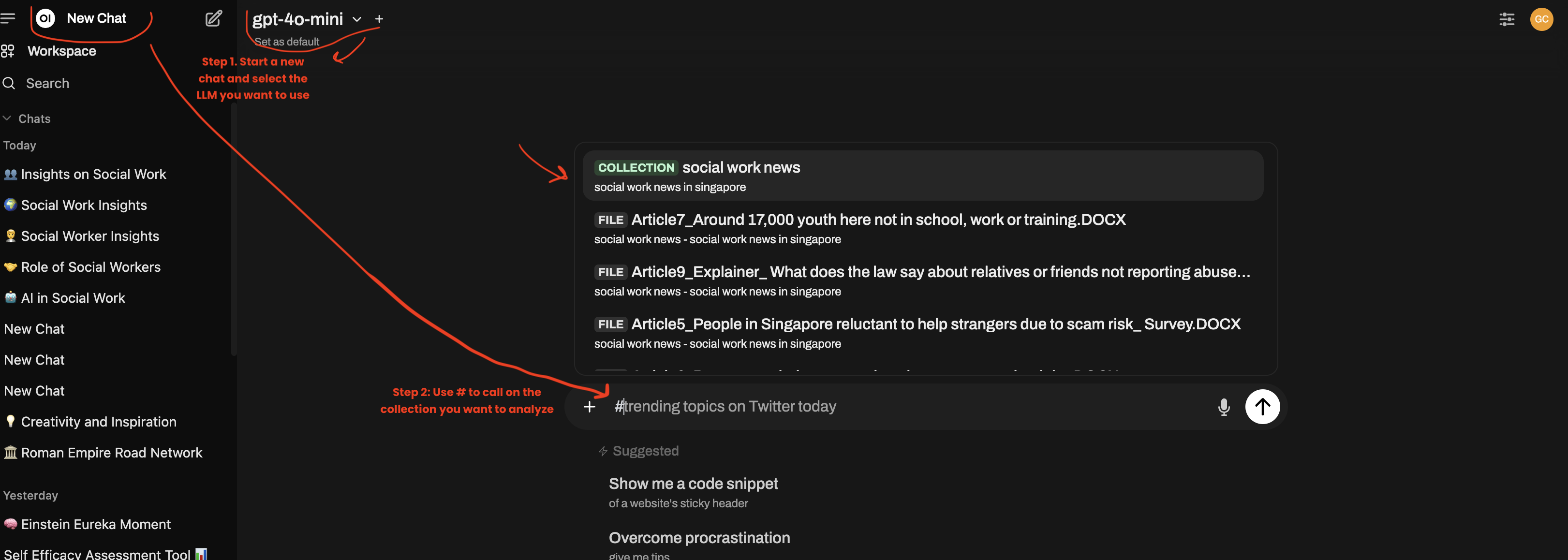
Step 5: Start a new chat and hashtag # your collection!
- Start a new chat. Select the LLM you want to use. It can be any models
- In this case, I will use gpt-40-mini.
- Use hash-tag
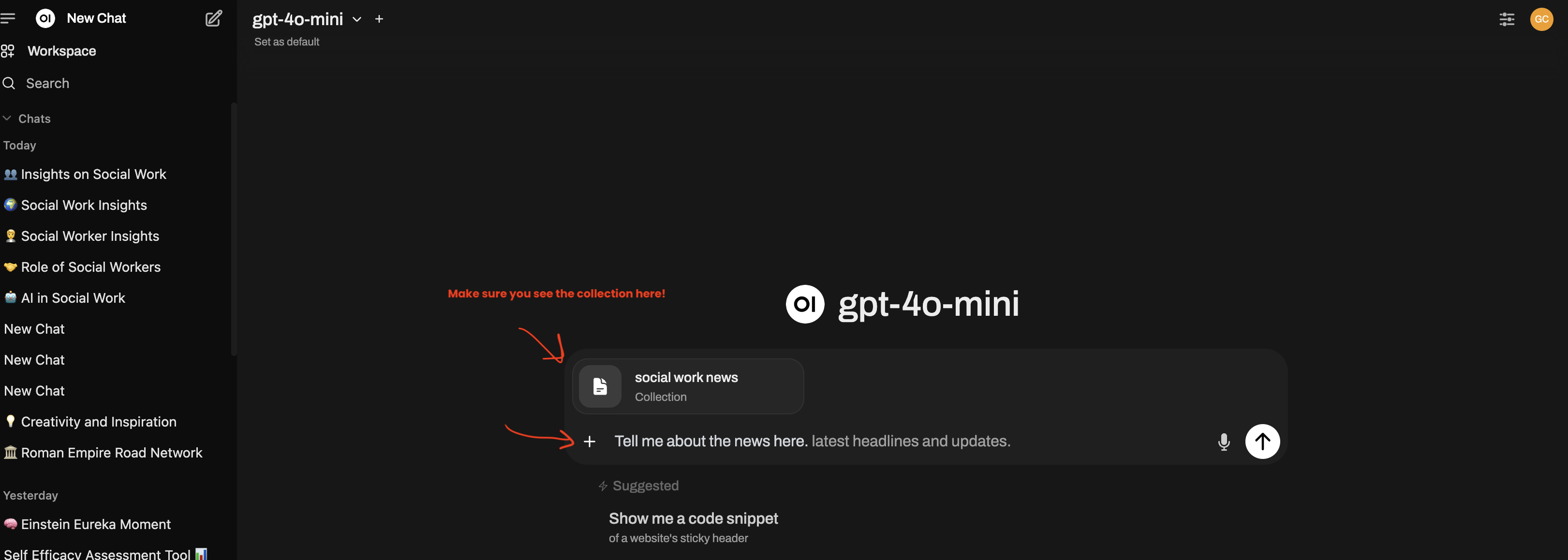
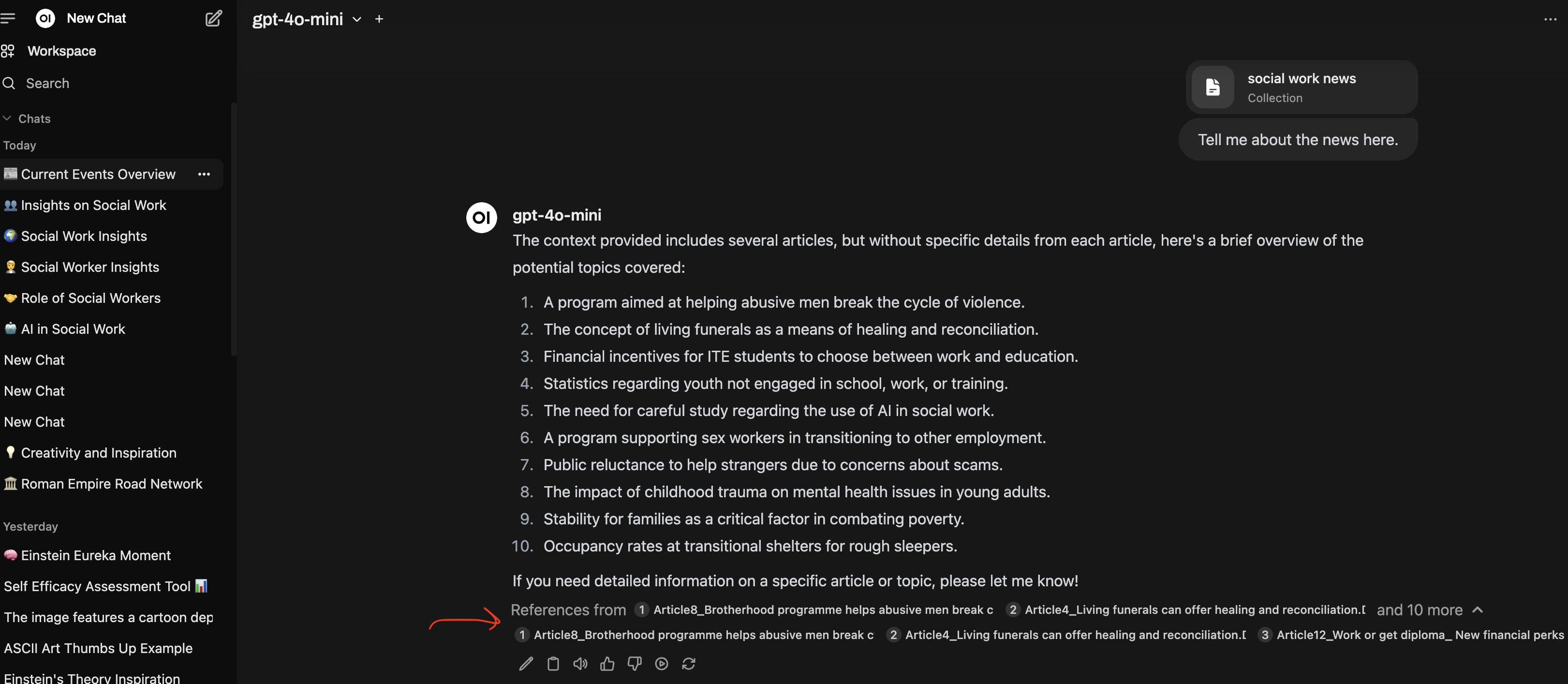
#to call on your collection that you want to use. - Then enter your prompt, e.g., a question you want the LLM to answer about your collection
Step 6: Change the parameters of your RAG
This step is optional. But if you feel that the rag is not giving you a good response, changing the parameters will improve the rag quality.
RAG is still a technology in development. There are new methods of RAG being develop right now and hopefully we can get better features of RAG here.
To change the parameters:
Under “Query Params”:
- Increase the “Top K” value from 3 to the number you might want.
- For e.g. for this example, I put k > 12 because i wanted more search hits
- Change the prompt if you need to.
- Maybe keep a copy of the original prompt saved somewhere as a backup
- There are other options that you can tinkle with but is beyond what I can teach here.
- See the video below
Under “Chunk Params”:
- Change the chunk size according to your documents. I used 100 here
- Change the chunk overlap. I used 20 here.
Click “Save” and see if this helps improve the quality of your rag.
To understand these paramters is beyond what i can do here. But do look at the video below. It is a little more technical. But it is doable! Maybe in the self-directed learning seminar, you can learn RAG!!!
Talk to me if you need help.