Downloading Ollama (Do this first)
Please do not share website content, slides, or notes with anyone else who are NOT taking this course now. This is my own intellectual work and I hope you can respect that.
Why do I need Ollama  ?
?
Ollama allows you to run LLM models on your computer. While Ollama can be used with the terminal app in our laptop, it is a bit challenging to do so.
This is why we will use OpenWeb UI to implement Ollama in a user-friendlier manner. To use OpenWeb UI, we will have to install Docker and then use Docker to install OpenWebUI and integrate Ollama.
Basically, download Ollama in the first step. Then download Docker and set it up next in the second step.
However, just two months ago in August 2025, Ollama released a chat UI in the download. This certainly makes using LLMS easier. Thus, you do not now have to use Open WebUI to interact with the LLMs. However, there is still a major limitation with just using the Ollama’s Chat UI which we will talk in class.
Steps to download Ollama
Ollama is free and easy to download. The steps below will show you how to download Ollama. Still have problems? I am only an email away.
Step A Download Ollama here
- Download Ollama (50MB) at https://ollama.com/ (takes up about 125MB for Mac in harddrive storage)
- Installation screenshots below are for Windows but probably similar to Mac
Ollama is technically just a process. It runs in the background.
By default, Ollama (also Docker later on) should only run when you fire up the app. But do check that the app does not auto-launch when you start up your laptop so that it does not take up your device memory if you are not using the app.
Next step is to interact with a very small size LLM: See below local model on downloading Google’s gemma3:270m!
Try interacting with LLMs using:
The APP’s CHAT UI (or user interface)
As explained above, only recently OllAMA released a chat UI to make it easier to interact with the LLMs. You can already try it if you want with the steps below. However, this chat UI is not our focus here because we want to tailor apps for our use cases. Nonetheless, you can already start playing with local or cloud LLMs!

Look for the Ollama app on your laptop, and open it. If you are using the Chat UI, it all looks familiar to you, right?
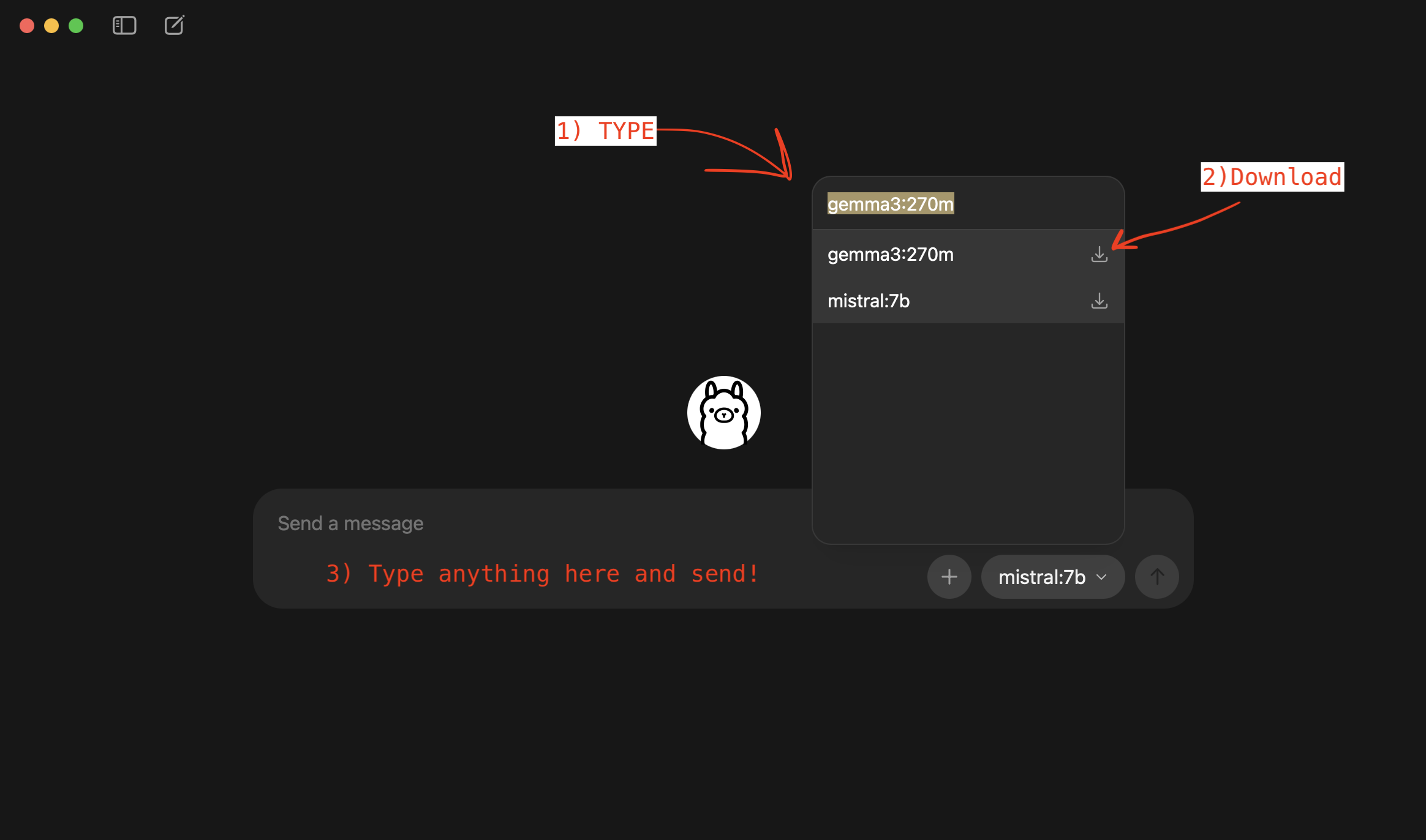
Click to start a new chat.
If you just started new with Ollama, you will NOT see any models in the drop-down box (e.g., in my screen-shot you see mistral:7b because I already have downloaded the model).
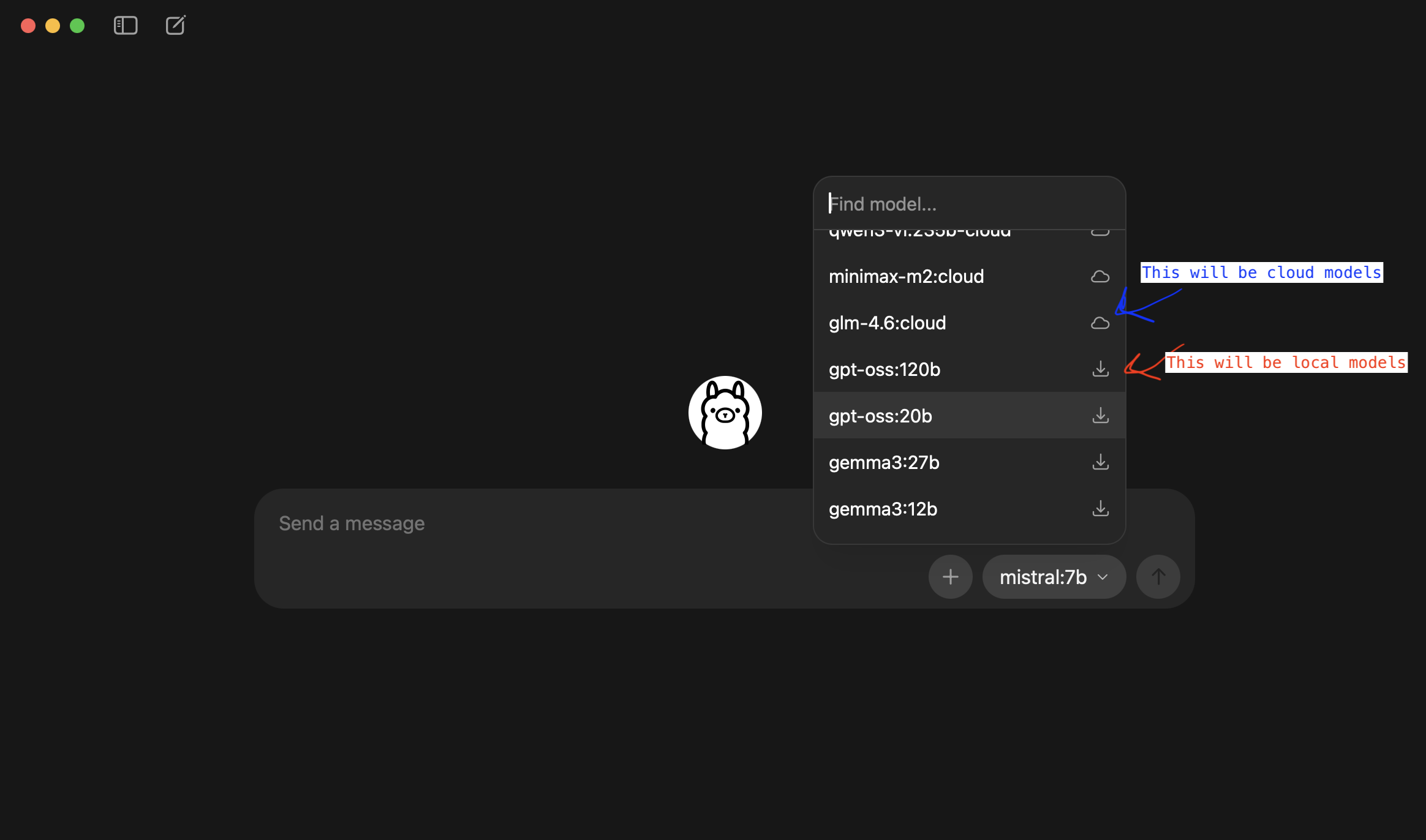
You have two choices: cloud models or local models.
CLOUD MODELS
If you use cloud models, these are likely to be very huge models and/or closed-sourced models and/or latest models. Thus, OLLAMA hosts these models in their cloud servers. If you want to use these models, you need to create an account, then choose a free or paid plan before using the models.
I think cloud models can be very useful. However, you should NOT use them if your data is NOT allowed to be transferred out of your devices because the data will be sent out to external servers.
Read this for more information!
LOCAL MODELS
Local models mean… it will be downloaded and local to only your computer. This is what we are here for in this course.
Since this is the first time you downloaded OLLAMA, you will NOT have any LOCAL models on your device. You have to download it.
Let’s type gemma3:270m in the model drop-down list and click on the download button. Note that even a small model of 270 million parameters like gemma3:270m is still about 280MB of storage.
Type something in the chatbot and send in. You will see the model being downloaded.
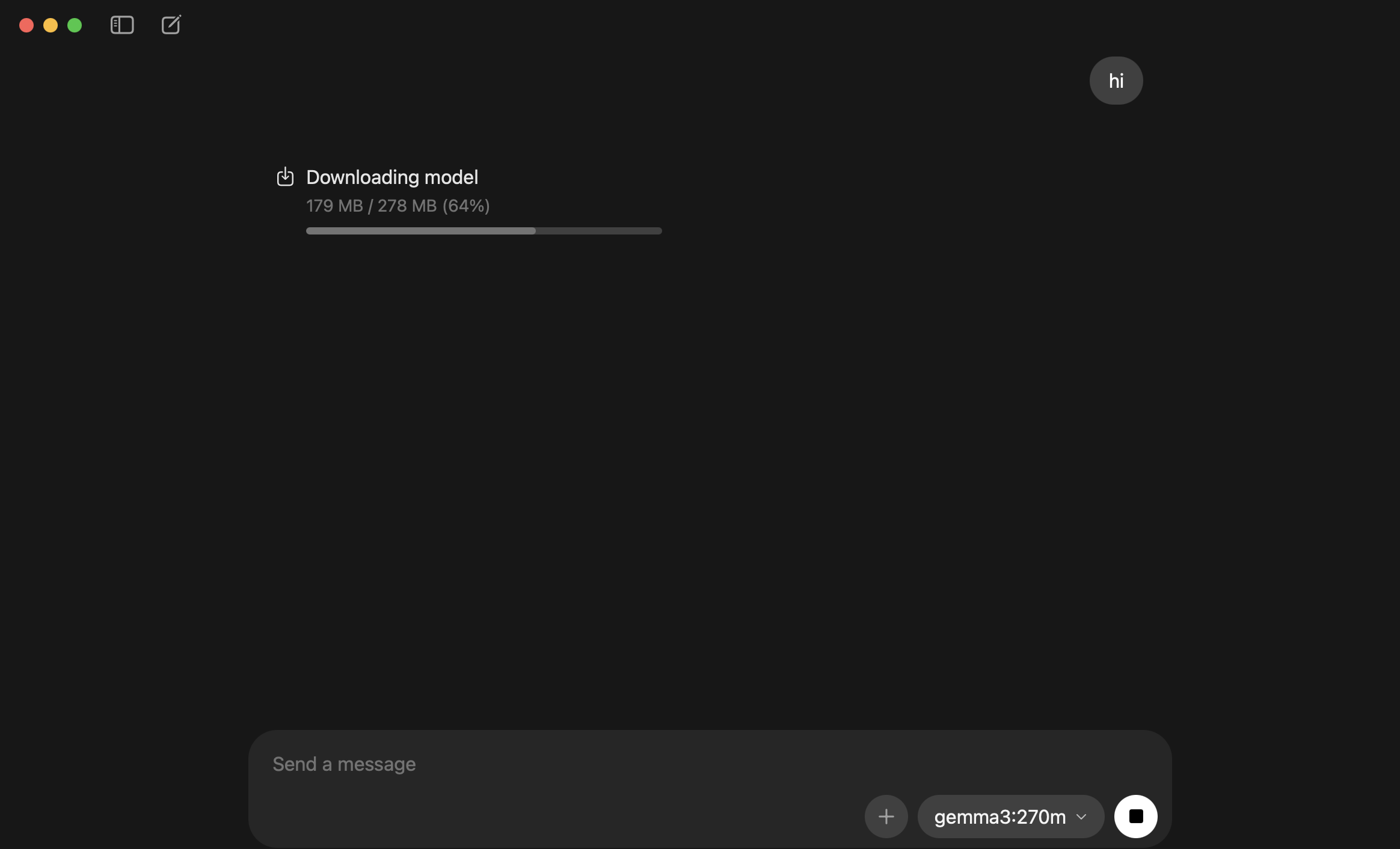
YAY!! you have downloaded your first local LLM and you can start interacting with the LLM
For this course, You should set-up Docker next.
Try using a Terminal (macOS) or Windows Terminal / Command Prompt (on Windows) to interact with LLMs via Ollama.
We will install and use OpenWeb UI to run LLMs on Ollama. BUT if you want to, you can actually run LLM on Ollama using your terminal.
Open Terminal (macOS) or Windows Terminal / Command Prompt (on Windows).
Type: ollama run gemma3:270m and enter
Note: you should have download the model first. If you have not, either use the previous step or run this command in the termina/command prompt first: ollama pull gemma3:270m
Watch this video if you want to try. Or you can also look at this commands in Ollama’s documentation here.
Do note one thing: small LLMs like phi or tinyllama still requires about 1GB harddrive space.